Dataset
The quality of a Speech Emotion Recognition (SER) system depends heavily on the dataset it is trained on. Emotions are
complex and can vary significantly between speakers based on voice, age, gender, accent, and context. A diverse and
well-structured dataset helps the model learn these subtle variations and improves its ability to recognize emotions
in real-life situations. In this project, I selected two widely recognized datasets in the field of emotion recognition:
CREMA-D and IEMOCAP. These datasets were chosen because they complement each other in terms of emotion range, speaker
diversity, and recording styles.
The CREMA-D dataset contains over 7,000 audio-visual recordings from 91 professional actors, covering a range of emotions
such as anger, fear, happiness, sadness, and neutrality. Each recording is annotated through crowd-sourced evaluations,
ensuring reliable emotion labels. On the other hand, the IEMOCAP dataset offers approximately 12 hours of both scripted
and spontaneous conversations performed by 10 actors. It includes a wide set of emotional categories and features both
acted and naturally expressed speech, making it especially valuable for building systems that need to work in dynamic,
real-world environments.
By combining these two datasets, the training set benefits from both the clarity and consistency of acted emotions and
the realism of spontaneous speech. This hybrid approach enhances the model’s ability to generalize beyond training data,
making it more useful in real-world applications such as virtual assistants, mental health tools, and emotion-aware user
interfaces.
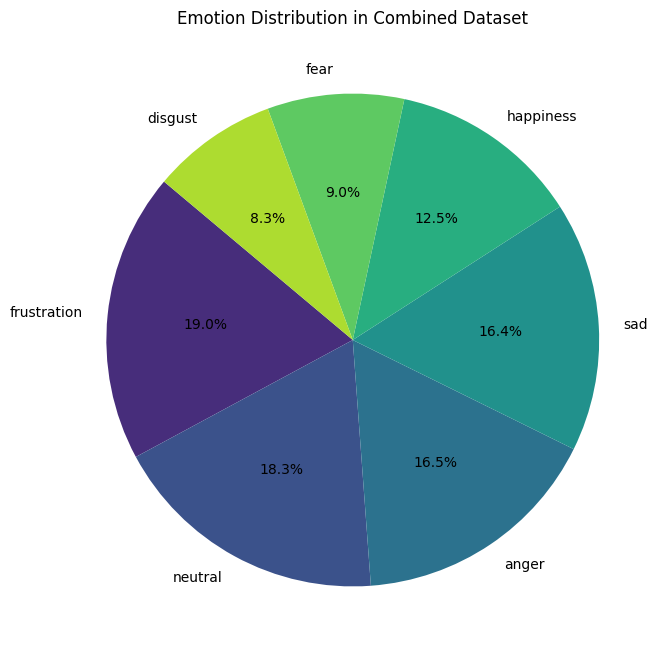
The pie chart on the left represents the distribution of emotions in the combined dataset, showing the percentage of
samples for each category. The largest portions belong to frustration (19%), neutral (18.3%), anger (16.5%),
and sad (16.4%), which are relatively well balanced. However, emotions like happiness (12.5%), fear (9.0%),
and disgust (8.3%) are clearly underrepresented.
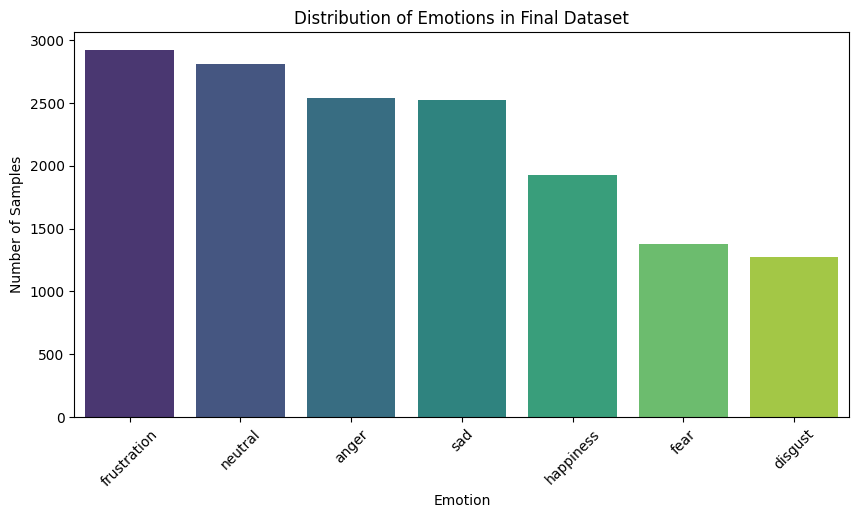
The bar chart on the right gives a more detailed view of how many audio samples exist for each emotion.
This chart helps visualize the actual data volume behind the percentages and confirms that fear and disgust appear
far less frequently compared to other emotions.
To improve the balance of the dataset and avoid model bias toward the more frequent emotions, I will remove the fear and
disgust categories entirely. Additionally, I will apply data augmentation techniques to the happiness samples to boost
their count and help the model better recognize this emotion during prediction. This preprocessing step is important for
building a model that can fairly and accurately recognize all intended emotional states.
Data Augmentation
Data augmentation is a technique used to increase the amount and diversity of training data by applying small,
controlled modifications to existing samples. In the context of speech emotion recognition, this helps the model
become more robust and better at generalizing across different voices, speaking styles, and recording
conditions — without requiring the collection of new data.
This process is particularly useful when working with imbalanced datasets, where some emotions (such as happiness)
are underrepresented. By augmenting these minority classes, we can help the model learn to recognize them more reliably.
Below are examples of different augmentation methods applied to the same audio sample:
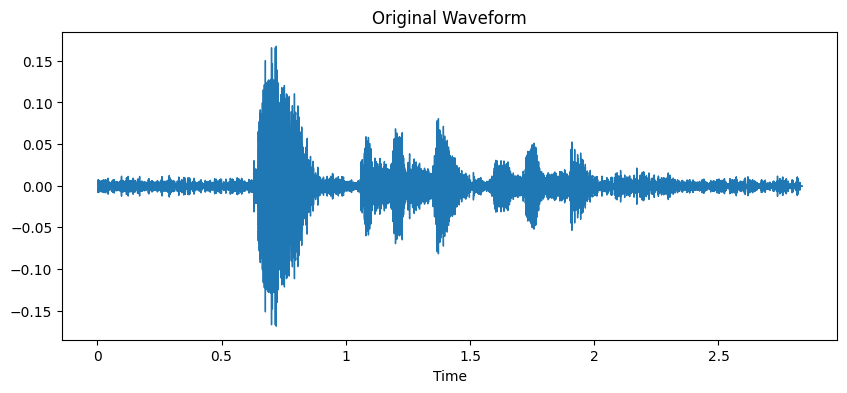
Original Waveform: This waveform represents the unaltered audio recording. It reflects the speaker’s natural expression of emotion and serves as the baseline for comparison with the augmented versions.
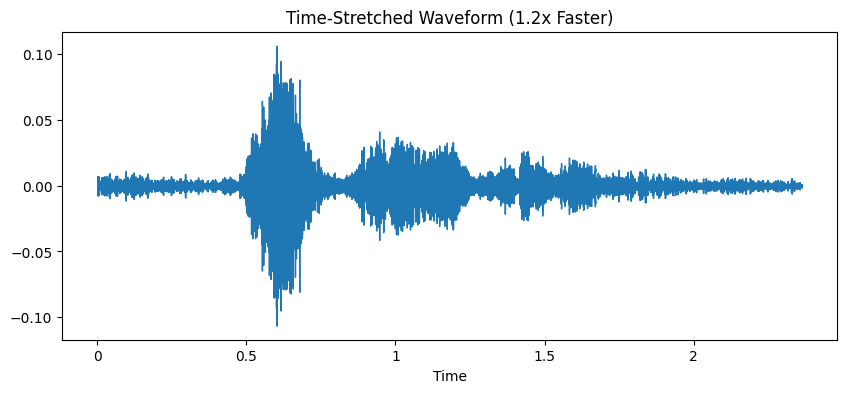
Time-Stretched (1.2x Faster): In this version, the audio is played 20% faster than the original. Time-stretching changes the speed of the speech while preserving its pitch. This simulates natural variation in speech rate and helps the model handle faster speakers without losing the emotional content.
Pitch-Shifted (+2 Semitones): Here, the pitch of the speaker’s voice is increased by two semitones, making it sound slightly higher. This type of augmentation mimics the diversity in vocal range found across speakers (e.g., differences in age, gender, or tone), allowing the model to learn that the same emotion can be expressed in different vocal characteristics.
Noise Added: A small amount of background noise is added to simulate real-world acoustic environments, such as ambient sounds or microphone interference. This improves the model’s ability to function in less-than-ideal recording conditions, which are common in real-life applications.
Final Dataset
To address class imbalance and help the model learn underrepresented emotions more effectively, I applied data augmentation techniques to the happiness category. These included speeding up audio, pitch shifting, and adding background noise — all while preserving the emotional content of the original speech. This process created a greater variety of samples, giving the model more examples to learn from.
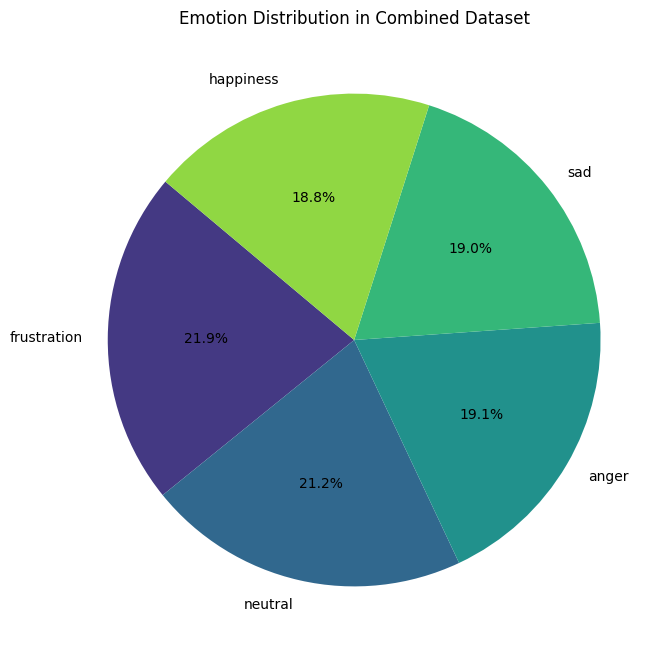
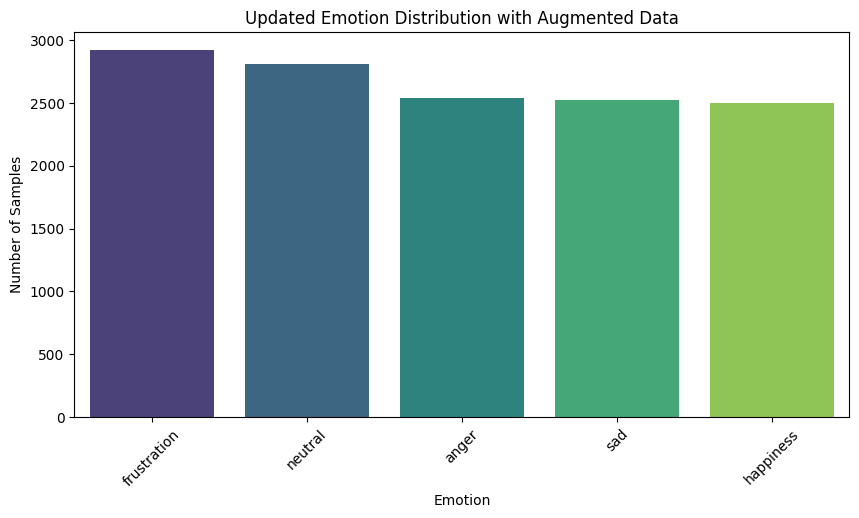
The bar chart shows the updated emotion distribution, where all emotions are now more evenly represented. Frustration and neutral still have slightly more samples, but now happiness, sad, and anger are closely aligned in terms of quantity — reducing the risk of model bias toward any single emotion. The pie chart confirms this balance visually, with each emotion occupying a similar portion of the dataset. The overall distribution is now far more consistent than before augmentation.